這一章繼續介紹剩下的兩種巨集:預先定義的巨集函式和字串假指令、重複區塊。然後還要介紹與巨集搭配後能產生強大功能的條件組譯。最後解析大神級的前輩,搭配巨集與條件組譯,所製作巨集,invoke。它能以一行程式碼,就能達成呼叫 Win64 API 的功能。
自 MASM 6.0 版開始,提供了四個預先定義的巨集函式:①@SizeStr、②@SubStr、③@InStr、④@CatStr,它們在巨集中處理字串非常好用。這四個預先定義的巨集函式,都有功能相同的假指令與之對應,分別是:①SIZESTR、②SUBSTR、③INSTR、④CATSTR。
要注意的一點是,如果原始程式有「OPTION CASEMAP:NONE」或是以 ML64.EXE 組譯時有下達「/Cp」選項區分大小寫時,那麼使用預先的義巨集函式,函式名稱要區分大小寫;而字串假指令不受限制。而不幸的是,以組合語言撰寫 Windows 程式,必定會區分大小寫,所以在引用這四個巨集函式時,大小寫必須依照前面的方式。除此之外,顧名思義,這四個預先定義的巨集函式為函式,因此必須依引用巨集函式的規定使用,其引數必須以一對「(」、「)」括起來。
@SizeStr 與 SIZESTR 都是用來計算一個字串有多少個位元組,先說 @SizeStr 的用法,它的其語法如下:
@SizeStr(string)
@SizeStr 巨集函式會把 string 字串裡含有多少個位元組作為回傳值,而且此回傳值是數值字串,並非數值,使用時必須注意。
@SizeStr 的 string 可以是字串常數或字串變數,也可以是字串本身。如果 string 是字串常數或字串變數,必須在其名稱之前加上展開運算子 ( 也就是「%」),否則得到的是字串常數名稱或字串變數名稱的長度。如果 string 是字串本身,就不須再加上展開運算子,可以以一對「<」、「>」將字串括住,也可以不用括住。當然,如果字串本身有一些特殊字元 ( 例如空白、引號 (")、逗號 (,)、單引號 (')……,甚至還要加上字元運算子 ),就必須以「<」、「>」將字串括住。例如:
beauty TEXTEQU <閉月羞花> len1 TEXTEQU @SizeStr(%beauty) ;;len1="8",一個中文字代表兩個位元組 len2 TEXTEQU @SizeStr(beauty) ;;len2="6" len3 TEXTEQU @SizeStr(<閉月羞花>) ;;len3="8" len4 TEXTEQU @SizeStr(閉月羞花) ;;len4="8"
上面第一行程式碼宣告了字串常數 buauty 等於「閉月羞花」,beauty 為字串常數的變數名稱,「閉月羞花」為其值。
SIZESTR 假指令的語法是
name SIZESTR string
SIZESTR 會把 name 變數之值設定為 string 字串所含的位元組個數,這裡的 name 是數值變數。string 可以是字串變數,也可以是字串本身;如果是字串變數,不需要加上展開運算子;如果是字串本身,必須以一對「<」、「>」將字串括住。SIZESTR 的效果有兩個:①求得之後運算元有多少位元組、②跟第一章「=」的效果類似,都是將數值指定給某個數值變數。延續上面的例子:
len5 SIZESTR beauty ;;len5=8 len6 SIZESTR <閉月羞花> ;;len6=8
上面的程式碼計算 beauty 字串有多少位元組,這裡的有多少位元組跟前面不同,它是數值。
@InStr 與 INSTR 都是在一個指定的字串中搜索一個較短字串的出現位置,此較短字串一般稱為「子字串」。先說明 @InStr,它的語法是:
@InStr( [start], string, short_string )
上面的 string 是指定的字串,short_string 則是要搜索的較短字串;此二者可以是字串常數或字串變數,也可以是字串本身。如果是字串常數或字串變數的話,前面要加上「%」,否則 @InStr 會把字串變數的名稱當做字串;如果是字串本身,可以一對「<」、「>」將字串括住,也可以不用,但如果字串本身有特殊字元,就必須以「<」、「>」將字串括住。
start 表示要在 string 字串中的第幾個位元組開始搜索,此處字串開始位置是一,並非組合語言慣用的零開始。如果省略 start,則假定由位置一處開始搜尋,也就是從頭開始搜尋,此時在 string 之前的「,」不可省略。如果 @InStr 找不到較短的字串,那麼回傳值為 0,否則就是在第幾個位元組找到了較短字串。@InStr 的回傳值是數值字串。
例如底下的例子是在「斷橋相約,觸手已化蝶。看滿山紅葉,可是離人眼中血」字串中尋找「相約」。程式碼如下:
formless TEXTEQU <斷橋相約,觸手已化蝶。看滿山紅葉,可是離人眼中血> date1 TEXTEQU @InStr(1,%formless,相約) date2 TEXTEQU @InStr(,斷橋相約,觸手已化蝶。看滿山紅葉,可是離人眼中血,相約)
上面的 date1 與 date2 是一樣的,最終兩者之值均為 "05",且均為字串。( 注意!一個中文字佔有兩個位元組 )
字串假指令 INSTR 的語法是:
name INSTR [start,] string, short_string
INSTR 的 string、short_string 意義與 @InStr 相同,都可以是字串變數或字串本身。如果是字串變數,前面不能加「%」,加了會產生錯誤;如果是字串本身,必定要以一對「<」、「>」將字串括住,否則也會產生錯誤。如果省略 start 的時候,由字串開始處搜尋,同時 start 之後的「,」必須一同省略。最後所得的結果,name,是數值變數,並非數值字串。例如底下兩行:
date3 INSTR formless,<相約> date4 INSTR <斷橋相約,觸手已化蝶。看滿山紅葉,可是離人眼中血>,<相約>
date3 與 date4 都是 5,兩者都是數值。
@SubStr 與 SUBSTR 都能從一個字串中,提取其中的一部分,形成新的字串。先說 @SubStr,它的語法是:
@SubStr( string, start [, length] )
@SubStr 的第一個參數是 string,可以是字串變數或字串常數,也可以是字串本身。如果是字串常數或字串變數的話,前面要加上「%」,否則 @SubStr 會把字串變數的名稱當做字串;如果是字串本身,可以一對「<」、「>」將字串括住,也可以不用,但如果字串本身有特殊字元,就必須以「<」、「>」將字串括住。
@SubStr 會在 string 字串中,由 start 開始 ( string 中的起頭字元,位置為一,與組合語言慣用的開始位置為零不同 ),長 length 個位元組,形成的新字串。length 可以省略,如果省略的話,新的字串由 start 開始至 string 結尾。
字串假指令 SUBSTR 的語法是:
name SUBSTR string, start[[, length]]
SUBSTR 的 string、start、length 都跟 @SubStr 一樣。底下的例子:
spider_man TEXTEQU <With great power, comes great responsibility> greatp1 TEXTEQU @SubStr(<With great power, comes great responsibility>,6,11) greatp2 TEXTEQU @SubStr(%spider_man,6,11) greatr1 SUBSTR <With great power, comes great responsibility>,25 greatr2 SUBSTR spider_man,25
上面的例子中,greatp1、greatp2 都是 "great power";greatr1、greatr2 都是 "great responsibility"。很明顯,@SubStr 與 SUBSTR 的結果,都是字串。
@CatStr 與 CATSTR 都能把數個字串連接起來,形成一個新的長字串。它們的語法是:
@CatStr( string1[, string2[, string3...]] ) name CATSTR string1[, string2[, string3...]]
它們都能把 string1、string2、string3……連接起來,而造出新的字串,@CatStr 將此新的字串作為回傳值;CATSTR 把 name 變數之值設為此新的字串。看底下的例子:
peom1 MACRO string
.DATA
DB @CatStr(<!">,%string,<小橋流水人家。!">)
ENDM
peom2 MACRO string
.DATA
temp CATSTR <!"古道西風瘦馬,>,<&string&>,<斷腸人在天涯。!">
DB temp
ENDM
在資料區段中以下面方式引用 peom1、peom2 巨集:
peom1 <枯藤老樹昏鴉,> peom2 <夕陽西下,>
就會在資料區段中產生一個字串:
DB "枯藤老樹昏鴉,小橋流水人家。古道西風瘦馬,夕陽西下,斷腸人在天涯。"
值得一提的是,在上面以一對「<」、「>」括住的字串中,如果有引號,也就是「"」,需在前面加上「!」,不然的話的「"」會讓組譯器以為字串結束。同樣的,「'」也是如此。
在巨集中使用這四個預先定義的巨集函式與字串假指令很麻煩,尤其是使用變數、參數的方式不同,其結果的資料類型也不同。小木偶也不知道為何要這麼麻煩,因此整理成下表:
| 變數 | 參數 | 字串 | 結果 | |
| 巨集函式: @SizeStr @InStr @SubStr @CatStr | 必須在變數名稱前加「%」 | 可以直接使用,或在參數名稱前加「%」 | 可以直接使用,但字串含有特殊字元就必須以「<」、「>」將字串括住 | 均為字串 |
| 字串假指令: SIZESTR INSTR SUBSTR CATSTR | 直接使用 | 必須以「<」、「>」將參數名稱括住;或者以「<」、「>」將參數名稱括住外,還要在參數名稱前後加上「&」 | 必須以「<」、「>」將字串括住 | SIZESTR、INSTR為數值 SUBSTR、CATSTR為字串 |
ML64.EXE 可使用的重複區塊有:①WHILE/ENDM、②REPEAT/ENDM、③FOR/ENDM、④FORC/ENDM,共四種。
WHILE/ENDM 的語法是:
WHILE 判斷式 敘述 ENDM
WHILE/ENDM 會先檢查判斷式是否為真,假如為假就跳到 ENDM 之後;假如為真就組譯 WHILE 與 ENDM 之間的敘述,至敘述的最後一行,然後回到 WHILE 處,再度檢查判斷式是否為真,依其真假判斷是否重複;如此一直到判斷式為假時,才跳出 WHILE/ENDM 迴圈。上面的敘述可以是 x86 指令或是符合組合語言語法的假指令。
判斷式有三種形式:
①:可以是數值關係式,其形式為:
number1 比較運算子 number2
number1 與 number2 可以是算術運算式或是組譯時期的變數、常數。常用的比較運算子有下列六種:
LT 小於 NE 不等於 LE 小於或等於 GT 大於 EQ 等於 GE 大於或等於
②:可以是數值關係式之間,再做複雜的邏輯運算,可用的邏輯運算子有 AND、OR 及 XOR。( 此三個邏輯運算子並非 x86 指令,僅用於判斷式裡面 )。
③:可以是一個組譯時期的變數或數學運算式。事實上,當組譯器對判斷式進行判斷時,如果最後結果為真,是以非零值代表 ( 通常是一 );如果最後結果為假,以零代表。
例如底下的 Fibonacci 巨集,就能在資料區段內定義一個不超過指定數值的費式數列 ( Fibonacci Sequence ),若此數值超過一萬,以一萬為限。所謂的費氏數列的前兩項是 0、1,從第三項開始,每一項都是前兩項之和。費氏數列的前十項是 0、1、1、2、3、5、8、13、21、34,可以一直無窮延伸,是無窮數列。
底下是 Fibonacci 巨集的內容:
Fibonacci MACRO number
x=0
y=1
z=x+y
f_sequence DW x,y
WHILE (z LE number) AND (z LT 10000) ;;當z小於或等於number且z小於一萬,才組譯WHILE至ENDM之間的程式碼
DW z
x=y
y=z
z=x+y
ENDM
ENDM
如果以下面方式引用
.DATA Fibonacci 100
就會在資料區段內產生「f_sequence DW 0,1,1,2,3,5,8,13,21,34,55,89」程式碼。如果以「Fibonacci 15000」引用,那麼這裡的費氏數列最多也只能到 6765。
上面的 Fibonacci 的判斷式不寫成「z LE number」,而寫成上面那樣的原因,其主要目的就是限制最多不可超過 10000。當然你可以把這個數改大一點,只需將 10000 改成大一點的數即可。
稍稍地解釋 WHILE 與 ENDM 之間的程式。因為費氏數列從第三項開始,每一項都是前兩項之和,所以從第三項之後的每一項就跟前兩項有關。當計算完某一項 ( 第 n 項 ) 之後,要計算下一項 ( 第 n+1 項 ),就只跟此項 ( 第 n 項 ) 與前一項 ( 第 n-1 項 ) 有關。也就是說,在計算第 n+1 項時,第 n-2 項就能拋棄。
這種情形,就很像踏著一排露出水面的石頭過河一樣,你的兩隻腳踏著兩塊石頭,每前進一步就捨棄後面的石頭,所需的石頭往前移一格。在 WHILE 與 ENDM 之間的程式也是如此,每計算完一項,前一項就變這一項,程式中的 x=y、y=z 就是用來往前移一格的,新的一項就是由 z=x+y 產生的。
REPEAT/ENDM 的語法是:
REPEAT 算術運算式 敘述 ENDM
算術運算式可以是常數或常數之間運算後的結果,它代表重複次數;也就是說 REPEAT 與 ENDM 之間的敘述會重複很多次,重複次數由算術運算式決定。請看底下的例子:
number LABEL DWORD
x=1
REPEAT 5
DD x DUP (x)
x=x+1
ENDM
上面的程式會產生底下的程式碼 ( 有關 LABEL 假指令的說明請參閱註一 ):
number DD 1,2,2,3,3,3,4,4,4,4,5,5,5,5,5
FOR/ENDM 的語法是:
FOR 參數,<引數一,引數二,引數三,……>
敘述
ENDM
組譯器會將引數一代入參數,組譯 FOR 與 ENDM 之間的敘述;然後再以引數二代入參數,組譯 FOR 與 ENDM 之間的敘述……如此一直重複,直到「<」、「>」內的引數全都代入過為止。
底下的程式碼,可以連續取得標準輸入裝置代碼、標準輸出裝置代碼、標準錯誤裝置代碼,並分別存入 hInput、hOutput、hError 三個變數裡 ( 這三個變數必須連續,且順序不能錯亂 ):
hInput DQ ?
hOutput DQ ?
hError DQ ?
⁝
lea r8,hInput
FOR nStd,<STD_INPUT_HANDLE,STD_OUTPUT_HANDLE,STD_ERROR_HANDLE>
mov rcx,nStd
call GetStdHandle
mov [r8],rax
add r8,SIZEOF QWORD
ENDM
首先把 hInput 的位址存入 R8 暫存器,然後進入 FOR/ENDM 重複區塊。第一次 nStd 是以 STD_INPUT_HANDLE 代入,得到標準輸入裝置代碼,存入 R8 所指的位址,此位址也是 hInput 變數所在位址。然後 R8 加上 QWORD 的大小,亦即指向下一個變數 hOutput 的位址,然後代入下個引數進行第二次循環。第二次 nStd 以 STD_OUTPUT_HANDLE,如此重複……直到第三個引數處理完,才離開 FOR/ENDM。
上面這段程式有個缺點,一般而言,呼叫 Win64 API 之後,R8 暫存器可能會被修改,這樣的話上面的巨集就不能用了。不過小木偶試過在 Windows 10 是沒問題的,但其他就不敢保證了。
上面的 FOR/ENDM 迴圈也可以用不確定參數數量的方式改寫,如下:
hInput DQ ?
hOutput DQ ?
hError DQ ?
⁝
GetHdl MACRO arg:VARARG
lea r8,hInput
FOR nStd,<arg>
mov rcx,nStd
call GetStdHandle
mov [r8],rax
add r8,SIZEOF QWORD
ENDM
ENDM
引用 GetHdl 的方法如下:
GetHdl STD_INPUT_HANDLE,STD_OUTPUT_HANDLE,STD_ERROR_HANDLE
FORC/ENDM 的用法和 FOR/ENDM 類似,但是其引數為字串而不是引數列表。FORC/ENDM 的語法是:
FORC 參數,<字串>
敘述
ENDM
FORC 從「<」、「>」內的字串中,每次取出一個字元,由第一個字元開始代入,組譯 FORC 到 ENDM 之間的敘述;然後再跳回到 FORC 處取出字串的第二個字元組譯……一直重複,直到字串的最後一字元處理完畢才算完成。假如 FORC/ENDM 是在另一個巨集內,而 FORC 後面接著的字串是該巨集的變數,那麼就要在 FORC 前面加上「%」,表示它是取出字串之值。如果不加上 %,結果會是變數名稱,並非字串內容,例子見下面左邊。假如 FORC/ENDM 在另一個巨集內,而 FORC 後面接著的字串恰好是該巨集的參數,那就不須在 FORC 之前加上 %,例子見下面右邊。
Tibetan1 MACRO lyrics1,lyrics2
i=0
lyrics CATSTR <lyrics1>,<lyrics2>
%FORC char,<lyrics>
j=i AND 1 ;使j在0、1之間切換,這是因為中文字由兩個
IF j EQ 0 ;位元組組成,第一次只儲存,第二次合併印出
temp TEXTEQU <char>
ELSE
temp1 CATSTR temp,<char>
%ECHO temp1 ;當j等於1時,才印出temp1
ENDIF
i=i+1
ENDM
ENDM
⁝
Tibetan1 <是誰帶來遠古的呼喚?>,<是誰留下千年的祈盼?> | Tibetan2 MACRO lyrics
i=0
FORC char,<lyrics>
j=i AND 1
IF j EQ 0
temp TEXTEQU <char>
ELSE
temp1 CATSTR temp,<char>
%ECHO temp1
ENDIF
i=i+1
ENDM
ENDM
⁝
Tibetan2 <難道說還有無言的歌?> |
執行完 Tibetan1、Tibetan2 之後,會在螢幕上垂直列出青藏高原的歌詞。
接下來再舉個 FORC/ENDM 的例子說明,但這個例子與萬國碼有關,所以先粗淺的說說萬國碼的編碼方式。萬國碼 ( Unicode ) 是一種字元編碼,它的企圖心很大,打算把全球所有文字都編成數值,藉以交換、顯示、處理全球文字。使用萬國碼已是世界的趨勢,將來的檔案都會採取這種編碼方式。
萬國碼也有許多種編碼方式,其中的 UTF-16 與 UTF-8 是最常見的編碼方式。對英文字母、阿拉伯數字等字元而言,UTF-16 只是把 ASCII 編碼方式,由一個位元組變成一個字組,高位元組均為零且低位元組就是 ASCII 碼。例如英文字母的「A」,其 ASCII 碼為 41H,僅一個位元組;而其 UFT-16 碼則為 0041H。底下的 WSTR 巨集,利用 FORC/ENDM 將僅含英文字母、阿拉伯數字等字元的 ASCII 字串轉換為 UTF-16 編碼方式。
WSTR MACRO str_name,ascii_str ;WSTR巨集能把英文字母或阿拉伯數字組成的ascii_str字串變成萬國碼字串。例如 ;WSTR szText,"Love" ;會變成 ;szText DB "L",0,"o",0,"v",0,"e",0,0,0 ;str_name-字串名稱 ;ascii_str-字串內容 str_len=@SizeStr(ascii_str) str_name LABEL WORD temp SUBSTR <ascii_str>,2,str_len-2 ;去除頭尾的「"」 %FORC char,<temp> DB "&char&",0 ENDM DW 0 ENDM
上面的 ascii_str 是僅含英文字母、阿拉伯數字等字元的 ASCII 字串。WSTR 巨集會在組譯時期,將 ascii_string 字串轉換成 UTF-16 字串,存於 str_name 字串變數裏,並且會自動在最後面添加一個字組的 0,表示結尾。例如在資料區段內,以下面方式引用 WSTR 巨集:
WSTR szLove,"I love you"
就會在資料區段產生底下的程式碼:
szLove DB "I",0," ",0,"l",0,"o",0,"v",0,"e",0," ",0,"y",0,"o",0,"u",0,0,0
至此,小木偶已將巨集介紹完畢,底下介紹條件組譯。
條件組譯是指在某些條件下,讓組譯器組譯某段程式,或者不組譯某段程式。組譯某段程式,就意味著會產生機械碼、依假指令指示組譯,並產生組譯時期的變數依此變數結果組譯,然後將上述所有結果寫入目的檔及可執行檔裡面 ( 當然組譯時期的變數,並不會寫入目的檔及可執行檔內 );反之,不組譯某段程式,就意味著不產生機械碼、也沒依假指令指示組譯,也不產生組譯時期的變數,當然也不會寫入目的檔及可執行檔裡面。條件組譯的假指令有好幾種,先介紹最常見的 IF/ELSE/ENDIF。
IF/ELSE/ENDIF 大概是最常見的條件組譯了,它的語法有兩種,分別介紹如下:
IF 判斷式
程式片段
ENDIF
上面的程式碼是說,如果判斷式為真,那麼就組譯程式片段中的程式,否則就不組譯。依據需要,IF 也可以搭配 ELSEIF、ELSE,語法為:
IF 判斷式一
程式片段一
ELSEIF 判斷式二
程式片段二
ELSEIF 判斷式三
程式片段三
⁝
ELSE
程式片段
ENDIF
上面的程式碼是說,如果判斷式一為真,那麼就組譯程式片段一中的程式;如果判斷式二為真,那麼就組譯程式片段二中的程式;如果判斷式三為真,那麼就組譯程式片段三中的程式……;如果都沒符合以上判斷式的條件,就組譯程式片段中的程式。如果不需要判斷這麼多條件,ELSEIF 可以視情況保留,也可以把到 ELSE 之前的敘述,都省略。判斷式的寫法與前述提及的 WHILE/ENDM 一樣,請自行參考。
底下舉兩個例子說明 IF/ELSEIF/ELSE/ENDIF 的應用。第一個例子可以在印出參數的資料類型。
prn_type MACRO argument
temp TEXTEQU <argument>
IF (TYPE temp) EQ 0
arg_type TEXTEQU <UNKNOWN>
ELSEIF (TYPE temp) EQ 1
arg_type TEXTEQU <BYTE>
ELSEIF (TYPE temp) EQ 2
arg_type TEXTEQU <WORD>
ELSEIF (TYPE temp) EQ 4
arg_type TEXTEQU <DWORD>
ELSEIF (TYPE temp) EQ 8
arg_type TEXTEQU <QWORD>
ENDIF
%ECHO arg_type
ENDM
⁝
number DD 10h,20h,30h,40h
⁝
prn_type number[rax*4+4]
在介紹第二個例子之前,先來介紹 SetConsoleCursorPosition Win64 API。SetConsoleCursorPosition 是設定命令提示字元的游標位置。如果沒有調整,那麼命令提示字元有 80 個字元寬,25 個字元高。寬可以看成是 X 座標,由 0 至 79;高是 Y 座標,由 0 至 24。由左上角座標為 ( 0,0 ),越往右 X 座標越大,越往下 Y 座標越大 ( 這與數學上的直角座標系相反 )。
SetConsoleCursorPosition 的原型是:
invoke SetConsoleCursorPosition,\
hConsoleOutput, ; handle of console screen buffer
dwCursorPosition ; new cursor position coordinates
hConsoleOutput 是標準輸出裝置代碼,可由用 STD_OUTPUT_HANDLE 為參數呼叫 GetStdHandle 的回傳值得到。dwCursorPosition 是要設定游標的位置,dwCursorPosition 的 0∼15 位元是 X 座標,16∼31 位元是 Y 座標。要注意的是,當命令提示字元視窗畫面填滿字元後,如果再有字元輸出到該視窗,那麼就會往上捲動。假設只往上捲動一列,這時候,視窗內左上角的座標是 ( 0,1 ),而 ( 0,0 ) 已經隱沒在視窗之外了。如果命令提示字元已經往上捲動,不論捲動幾列,這時再用 SetConsoleCursorPosition 將游標設置在第 0 列,那麼 SetConsoleCursorPosition 還是可以將第 0 列顯示於命令提示字元的視窗最上面一列。
底下的 GotoXY 巨集利用 IF/ELSE/ENDIF 在呼叫 SetConsoleCursorPosition 之前,先檢查 X 座標是否在 0∼79,Y 座標是否在 0∼24。如果均在此範圍,那麼就呼叫 SetConsoleCursorPosition,如果不在這範圍內,在組譯時期就印出「Cursor position is out of range.」訊息。底下是 GotoXY 巨集內容:
GotoXY MACRO handle,x,y
IF (x GE 0) AND (x LE 79) AND (y GE 0) AND (y LE 24)
mov rcx,handle
mov rdx,y
shl rdx,10h
add rdx,x
call SetConsoleCursorPosition
ELSE
ECHO Cursor position is out of range.
ENDIF
ENDM
如果用後面方式引用 GotoXY 的話:「GotoXY hOutput,0,100」,那麼 ML64.EXE 並不會組譯 IF 至 ELSE 之間的內容,反而會在組譯時期於命令提示字元內印出「Cursor position is out of range.」來。但這並不能代表錯誤,組譯器仍會繼續組譯原始程式剩下來的部分,也能製造出可執行檔來。如果要強迫組譯器終止組譯,可以在 ECHO 之後緊接著使用「.ERR」條件錯誤假指令。
IFE 的意義與 IF 相反,其語法是:
IFE 判斷式
程式片段
ENDIF
IFE 的意思是如果判斷式為假,則組譯程式片段中的程式。IFE 也可以搭配 ELSE 使用,其語法是:
IFE 判斷式
程式片段一
ELSE
程式片段二
ENDIF
上面的程式是說,如果判斷式為假,則組譯程式片段一;否則組譯程式片段二。
IFB/ELSE/ENDIF 與 IFNB/ELSE/ENDIF 也是常見的條件組譯假指令,它們一般用在巨集中,檢查引用巨集時是否有參數忘了輸入。先來看看 IFB/ELSE/ENDIF,它也有兩種語法,第一種是:
IFB <參數>
程式片段
ENDIF
IFB 是 if blank 的意思,參數必須在一對「<」、「>」之間。整段程式代表如果參數是空的話 ( 也就是沒輸入這個參數 ),那麼就組譯程式片段。也能視需要改成第二種語法,如下:
IFB <參數>
程式片段一
ELSE
程式片段二
ENDIF
整段程式是說,如果沒輸入參數的話,那麼就組譯程式片段一;否則組譯程式片段二。
與 IFB/ELSE/ENDIF 相反的是 IFNB/ELSE/ENDIF。IFNB/ELSE/ENDIF 也有兩種語法,第一種是:
IFNB <參數>
程式片段
ENDIF
IFNB 是 if not blank,整段程式代表如果參數不是空白的話 ( 也就有輸入這個參數 ),那麼就組譯程式片段。也能視需要改成第二種語法:
IFNB <參數>
程式片段一
ELSE
程式片段二
ENDIF
上述程式代表如果有輸入參數的話,就組譯程式片段一;否則組譯程式片段二。IFB/ELSE/ENDIF 與 IFNB/ELSE/ENDIF 除了檢查在引用巨集時,是否遺漏參數而做補救之外,也可以用來檢查某個字串變數是否為空的。在後面這種情況下,參數以字串變數名稱代替,並且不可以用一對「<」、「>」括住。底下的 TSTIFB.ASM 程式:
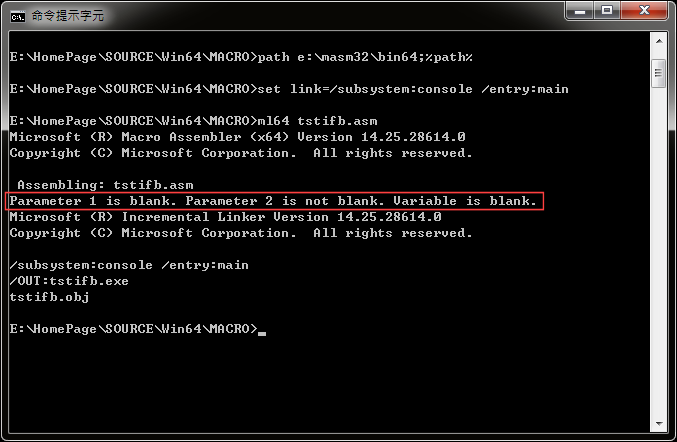
;TEST IFB:測試IFB假指令的程式 OPTION CASEMAP:NONE EXTRN ExitProcess:PROC INCLUDELIB e:\masm32\lib64\kernel32.lib TestIFB MACRO p1,p2 var_str TEXTEQU <> ;;var_str為空字串 ;;檢查p1參數是否為空的 IFB <p1> result1 EQU <Parameter 1 is blank.> ELSE result1 EQU <Parameter 1 is not blank.> ENDIF ;;檢查p2參數是否為空的 IFNB <p2> result2 EQU <Parameter 2 is not blank.> ELSE result2 EQU <Parameter 2 is blank.> ENDIF ;;檢查var_str字串變數是否為空的 IFB var_str result3 EQU <Variable is blank.> ELSE result3 EQU <Variable is not blank.> ENDIF %ECHO result1 result2 result3 ENDM ;************************************************* .CODE ;------------------------------------------------- main PROC TestIFB ,0 xor rcx,rcx call ExitProcess main ENDP ;************************************************* END
別看這個程式小就看輕它,它是個完整的程式可以正常組譯,而且還能執行。在組譯時,會印出「Parameter 1 is blank. Parameter 2 is not blank. Variable is blank.」,這是因為在 main 副程式的第一行,引用 TestIFB 時,沒有輸入第一個參數,但有輸入第二個參數,另外在巨集的第一行宣告 var_str 字串變數為空的,因此才會有這樣的結果。要注意的是,「0」也是代表有輸入參數,要空的才算是沒輸入。下圖是組譯 TSTIFB.ASM 的過程:
IFIDN/ELSE/ENDIF 的語法也有兩種,較簡單的是
IFIDN <參數1>,<參數2>
程式片段
ENDIF
IFIDN 中的 IDN 是「identical」的意思,參數1 與參數2 都必須以一對「<」、「>」括起來中間以「,」隔開。上述程式就表示如果參數1 和參數2 相同的話,就組譯程式片段。也可以視需要而使用第二種語法:
IFIDN <參數1>,<參數2>
程式片段一
ELSE
程式片段二
ENDIF
上述程式就表示如果參數1 和參數2 相同的話,就組譯程式片段一;否則組譯程式片段二。
IFIDNI/ELSE/ENDIF 比 IFIDN/ELSE/ENDIF 多了一個「I」,是表示在比較參數1 和參數2 時,忽略英文字母大小寫的不同,其他方面都一樣。另外,跟 IFB/ELSE/ENDIF 一樣,IFIDN/ELSE/ENDIF 與 IFIDNI/ELSE/ENDIF 也可以用於比較字串變數是否相等,如果是用於比較字串變數的話,那麼字串變數的名稱不可用一對「<」、「>」括起來。例如底下的例子:
REGARG MACRO arg,register
lead SUBSTR <arg>,1,5 ;;lead字串為arg的前五個字元
IFIDNI lead,<ADDR > ;;檢查lead字串是否為 "ADDR ",不管大小寫,若lead為 "Addr " 也算相等
pointer SUBSTR <arg>,6 ;;若相等,設pointer為arg第六個字元之後的字串
lea register,pointer
ELSE
mov register,arg
ENDIF
ENDM
REGARG 巨集可用於呼叫 Win64 API 時,傳遞前四個參數。由前面的 ReadConsole、WriteConsole 知道,這些參數有些是常數、有些是變數、有些是位址,如果是前二者只需用 MOV 指令,將其存入對應的暫存器即可;但如果是位址,本來可以用「MOV 暫存器,OFFSET」指令,但是 OFFSET 之後所接的變數只能在資料區段內,但往後會有許多情形會使用區域變數,因此最好是使用 LEA 指令求得位址。我們用「自製的運算子」,ADDR,來代表取得變數的位址,就成了上面的巨集。
IFDIF/ELSE/ENDIF 的語法也是:
IFDIF <參數1>,<參數2>
程式片段
ENDIF
IFDIF 中的 DIF 是「different」的意思,參數1 與參數2 都必須以一對「<」、「>」括起來中間以「,」隔開。上述程式就表示如果參數1 和參數2 不同的話,就組譯程式片段。也可以視需要成加強版:
IFDIF <參數1>,<參數2>
程式片段一
ELSE
程式片段二
ENDIF
述程式就表示如果參數1 和參數2 不同的話,就組譯程式片段一;如果相同的話,就組譯程式片段二。IFDIFI/ELSE/ENDIF 比 IFDIF/ELSE/ENDIF 多了一個「I」,是表示在比較參數1 和參數2 時,忽略英文字母大小寫的不同,其他方面都一樣。
IFDEF/ELSE/ENDIF 的語法是:
IFDEF 符號
程式片段
ENDIF
IFDEF 是 if defined 的意思,所以上面的程式是說,如果符號已定義或已宣告,就組譯程式片段。也可以依需要,把 IFDEF 寫成加強版:
IFDEF 符號
程式片段一
ELSE
程式片段二
ENDIF
上面的程式是說,如果符號已定義或已宣告,就組譯程式片段一;否則組譯程式片段二。
IFNDEF/ELSE/ENDIF 中,IFNDEF 的「N」是 not 的意思,所以 IFNDEF 合起來就是 if not defined。代表如果符號未定義或未宣告的話,則組譯 IFNDEF 至 ELSE 之間的程式碼,否則組譯 ELSE 至 ENDIF 之間的程式碼。它的語法也有兩種,如下:
IFNDEF 符號
程式片段
ENDIF
或
IFNDEF 符號
程式片段一
ELSE
程式片段二
ENDIF
底下的程式 TSTIFDEF.ASM 可以在組譯時,讓 ML64.EXE 依據是否宣告 UNICODE 變數來決定組譯成萬國碼的版本或是 ASCII 版本。先看完整的程式碼:
;TEST IFDEF:測試IFDEF假指令的程式 INCLUDE GREETING1.INC EXTRN WriteConsoleW:PROC IFDEF UNICODE WriteConsole TEXTEQU <WriteConsoleW> ELSE WriteConsole TEXTEQU <WriteConsoleA> ENDIF WStr MACRO str_name,len_name,ascii_string len_name DQ @SizeStr(ascii_string) str_name LABEL WORD FORC char,<ascii_string> DB "&char&",0 ENDM DB 0,0 ENDM ;string巨集可依是否定義UNICODE,把字串轉換成ASCII字串或萬國碼字串(僅限於英文 ;字母、阿拉伯數字……等)。轉換後的格式是: ;len_nam DQ 字串長度 ;strname DB 字串內容 ;例如引用時:「string sStr,cChr,<I love you>」,會造成底下程式碼 ; ASCII:cChr DQ 10 ; sStr DB "I love you",0 ;UNICODE:cChr DQ 10 ; sStr DB "I",0," ",0,"l",0,"o",0,"v",0,"e",0," ",0,"y",0,"o",0,"u",0,0,0 string MACRO strname,len_nam,sentence IFNDEF UNICODE len_nam DQ @SizeStr(sentence) strname DB "&sentence&",0 ;;ASCII字串兩旁要加「"」 ECHO MAKE ASCII EDITION ;;組譯時,顯示產生ASCII版 ELSE WStr strname,len_nam,sentence ECHO MAKE UNICODE EDITION ;;組譯時,顯示產生UNICODE版 ENDIF ENDM ;******************************************************************************* .DATA hOutput DQ ? chrWrt DQ ? string sStr,cChr,<I love you> ;******************************************************************************* .CODE ;------------------------------------------------------------------------------- main PROC GetStdH STD_OUTPUT_HANDLE,hOutput mov rcx,hOutput lea rdx,sStr mov r8,cChr mov r9,OFFSET chrWrt mov QWORD PTR [rsp+20h],0 call WriteConsole exit: Quit main ENDP ;******************************************************************************* END
宣告符號的地方通常是在原始程式裡,而且大部分情況下都是在原始程式前面,使用 EQU、=、TEXTEQU 等假指令宣告;或是放在包含檔中,以 INCLUDE 假指令將該包含檔加入。除此之外,也可以在組譯時期宣告,請見下面的說明。
微軟的巨集組譯器有個選項「/D」( 也可以寫成「-D」),能夠在命令提示字元底下輸入指令時,同時宣告符號及其初始值。宣告的符號及初始值,直接接在「/D」的後面,中間不可有空白,這樣就相當於在原始程式宣告了這個符號。
由以上的說明,要組譯 TSTIFDEF.ASM 可分為兩種不同的情況:
下圖中,都有操作這兩種情況: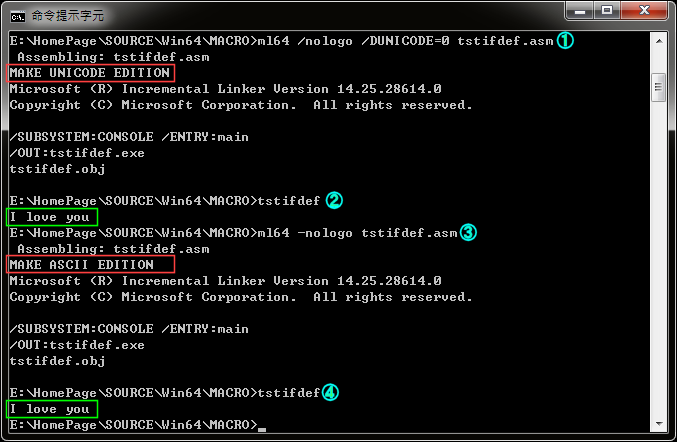
上圖的組譯過程還有三處值得說明:
GOTO 一般用於巨集之中,無條件跳躍至巨集標記處組譯,巨集的標記也使用「:」符號作為識別,其後接文字。這點與 x64 指令的 JMP、JZ……跳躍指令的目標不一樣的,x64 指令的標記是文字之後才接「:」。例如底下的例子:
NullStr MACRO str_name,string
len TEXTEQU @SizeStr(string)
IFIDN len,<02> ;;因為"也算字元,故有兩個
GOTO quit
ENDIF
str_name DB string
:quit
ENDM
.CONST
NullStr str1,""
NullStr str2,"紛飛燕,繁花絢,綻放艷如仙。"
NullStr 用來檢查應用程式定義的字串是否為空的,上面的 str1 就不會被組譯器定義於 .CONST 區段,str2 則會。
條件錯誤假指令可以用於除錯,檢查組譯時期的錯誤。這些假指令也可以用於巨集中,它們有 .ERR、.ERRE、.ERRNZ、.ERRDEF、.ERRNDEF、.ERRB、.ERRNB、.ERRIDN、.ERRIDNI、.ERRDIF、.ERRDIFI。
無條件強制產生錯誤,並終止組譯,於螢幕上印出「error A2052:forced error」訊息。
.ERRE 與 .ERRNZ 的語法是
.ERRE 判斷式 .ERRNZ 判斷式
.ERRE 是指如果判斷式為假,就發生錯誤,並終止組譯,於螢幕上印出「error A2053:forced error : value equal to 0」。.ERRNZ 是指如果判斷式為真,就發生錯誤,並終止組譯,於螢幕上印出「error A2054:forced error : value not equal to 0」。
.ERRDEF 與 .ERRNDEF 的語法是
.ERRDEF 符號 .ERRNDEF 符號
.ERRDEF 是指若符號已定義,就發生錯誤,並終止組譯,於螢幕上印出「error A2056:forced error : symbol defined」。.ERRNDEF 是指若符號未定義,就發生錯誤,並終止組譯,於螢幕上印出「error A2055:forced error : symbol not defined」。此處的符號包含變數名稱、副程式名稱、標記等。
.ERRB 與 .ERRNB 的語法是
.ERRB <引數> .ERRNB <引數>
這兩個假指令用在巨集中,用於檢測傳遞過來的引數是否空的。「引數是空的」的意思是指引用巨集時,沒有傳遞某些引數。.ERRB 是指如果該引數是空的,就發生錯誤;.ERRNB 是指如果該引數存在,就發生錯誤。
這四個假指令的語法如下:
.ERRIDN <引數1>,<引數2> .ERRIDNI <引數1>,<引數2> .ERRDIF <引數1>,<引數2> .ERRDIFI <引數1>,<引數2>
這四個假指令是比較引數1 與引數2 是否相同,「IDN」是相同的意思,「DIF」是不同的意思。因此「.ERRIDN <引數1>,<引數2>」是說,如果引數1 與引數2 相同,就會發生錯誤,並終止組譯,於螢幕上印出「error A2059:forced error : strings equal」。「.ERRDIF <引數1>,<引數2>」是說,如果引數1 與引數2 不同,就會發生錯誤,並終止組譯,於螢幕上印出「error A2060:forced error : strings not equal」。
假指令最後有添加「I」,表示比較時大小寫看成一樣,也就是不區分大小寫,例如「RAX」跟「rax」視為相同。這四個假指令通常用於巨集中,檢查傳遞進來的引數是否與預設的一樣。
經過第五、六兩章漫長的介紹,現在終於要進入重軸戲了--巨集有何用?小木偶想至少有兩個:①修正組譯器錯誤,參考附錄二、②增加組譯器功能,例如 invoke。本章僅說明後者。invoke 是先進利用巨集以及條件組譯打造出來的,它遵守 x64 呼叫慣例,可以用來呼叫 Win64 API,這樣就能簡化呼叫流程。在說明如何打造 invoke 之前,先說說它的歷史。
在微軟發售 MASM 6.x 的時候,正是 16 位元的作業系統 MS-DOS 功成身退,32 位元的 Windows 95/98 嶄露頭角之際。那時的組譯器稱為 ML.EXE,能開發 16 位元的 MS-DOS 程式以及 32 位元的 Windows 程式。微軟也是在此時,把 invoke 假指令加入到 ML.EXE 組譯器之中,之前版本並不支援 invoke。Win32 API 呼叫慣例稱為 STDCALL,invoke 僅需一行就能呼叫 Win32 API,發揮了很好的功用。到了 64 位元的 Win64 時代,開發 64 位元程式的組譯器是 ML64.EXE,而微軟卻把 invoke 從 ML64.EXE 刪掉了,所以前幾章裡才會用很麻煩的方法呼叫 Win64 API。小木偶打算先說說 ML.EXE 中 invoke 的用法,以及有什麼功能,再來介紹先進如何用巨集以及條件組譯來模擬它。
在 ML.EXE 中組譯 Win32 程式時,invoke 的語法是:
invoke 副程式名稱,參數列表
其中副程式名稱可以是 Windows API 的名稱,也可以是程式設計師所定義的副程式名稱。當然這些名稱都會被組譯器轉換成 Windows API 位址或副程式的位址。我們知道,事實上副程式名稱其實就是它的位址,所以在少數情形下,副程式名稱也可以是間接定址所指的位址。參數列表中,可能有許多參數,它們之間以「,」分隔。這些參數可分為四類:①暫存器、②常數、③變數之數值、④變數之位址。前三類較為單純直接寫出來即可,比較麻煩的是最後一類。
以 invoke 呼叫副程式時,如果要以某個變數位址當成參數的話,必須在變數前面加上 ADDR 運算子,ADDR 專門用於 invoke 的參數列表中,求出變數的位址。例如用 invoke 呼叫 WriteConsole 時,第二個參數是要印出的字串位址、第四個參數是變數位址,WriteConsole 會將實際上印出幾個字元存入該變數中,這兩個參數都必須用到 ADDR 運算子。如下式:
invoke WriteConsole,hOutput,ADDR string,SIZEOF string,ADDR chrWrt,0
一目瞭然,而且一行就解決了,是不是很簡單。但是,這是 32 位元的 Windows 程式;如要開發 64 位元的 Windows 程式,那可沒 invoke 可用。如果要以巨集、條件組譯重新打造一個 invoke 巨集,讓 ML64.EXE 恢復在 32 位元時代的 invoke 功能,那麼它的用法最好也跟上面一樣。也就是說,重新打造的 invoke 要讓 ML64.EXE 支援像上面的方式呼叫 Win64 API 或是自行定義的副程式,那就得要把「invoke WriteConsole,hOutput,ADDR string,SIZEOF string,ADDR chrWrt,0」展開後變成:
mov rcx,Output
lea rdx,string
mov r8,SIZEOF string
lea r9,chrWrt
mov QWORP PTR [rsp+32],0
call WriteConsole
從展開後的結果來看,ADDR 其實是使用了 LEA 指令,來求得位址,說穿了一點也不稀奇。
那麼,又要如何才辦到將 invoke 展開成這樣子的呢?底下小木偶試著來解讀包含檔中的 invoke 巨集。首先要找到 invoke 巨集在哪兒?根據 MASM64 的說法,原始程式的第一行通常是「include \masm32\include64\masm64rt.inc」,因此用文書處理軟體,例如 UltraEdit32,開啟 masm64rt.inc 觀察前幾行,如下:
OPTION DOTNAME ; required for macro files option casemap:none ; case sensitive include \masm32\include64\win64.inc ; main include file include \masm32\macros64\vasily.inc ; main macro file include \masm32\macros64\macros64.inc ; auxillary macro file
很幸運的,利用搜尋「invoke MACRO」,很快就在 macros64.inc 就找到了定義 invoke 巨集的地方,定義的方式下:
invoke MACRO fname:REQ,args:VARARG procedure_call fname,args ENDM
很明顯,invoke 的第一個參數是必要的,這當然,因為這是要呼叫 Win64 API 的名稱,而後面的參數數量則不固定。而 invoke 的內容僅僅一條,引用另一個巨集,procedure_call。這倒是出乎意料之外,本想 invoke 應該很複雜,沒想到卻是引用另一個巨集。於是再去尋找「procedure_call」,也很幸運,在 macros64.inc 內找著了,其宣告方式如下:
procedure_call MACRO fname:REQ,a1,a2,a3,a4,a5,a6,a7,a8,a9,a10, \
a11,a12,a13,a14,a15,a16,a17,a18, \
a19,a20,a21,a22,a23,a24,a25
LOCAL lead,wrd2,ssize,sreg,svar
;; ********************
;; argument count limit
;; ********************
IFNB <a25>
% echo ????************************************
% echo ????argument limit exceeded in procedure -> fname
% echo ????argument count limit of 24 arguments
% echo ????************************************
.err
goto function_call
ENDIF
;; **************************
;; first 4 register arguments
;; **************************
IFNB <a1>
REGISTER a1,cl,cx,ecx,rcx
ENDIF
IFNB <a2>
REGISTER a2,dl,dx,edx,rdx
ENDIF
IFNB <a3>
REGISTER a3,r8b,r8w,r8d,r8
ENDIF
IFNB <a4>
REGISTER a4,r9b,r9w,r9d,r9
ENDIF
;; **************************
;; following stack arguments
;; **************************
IFNB <a5>
STACKARG a5,32
ENDIF
IFNB <a6>
STACKARG a6,40
ENDIF
IFNB <a7>
STACKARG a7,48
ENDIF
⁝
IFNB <a24>
STACKARG a24,184
ENDIF
:function_call
call fname
ENDM
仔細觀察後,會發現 procedure_call 大致分成三部分:①紅色部分檢查是否超過 24 個參數,如果超過就發生錯誤。②藍色部分處理前四個參數。③綠色部分處理第五個及其以後的參數。
procedure_call 用 IFNB/ENDIF 檢查第 25 個參數是否存在,如果存在就表示超過 24 個參數,那麼就發生錯誤。小木偶不知道為何以檢查是否超過 24 個參數當做錯誤,猜想可能是 Win64 API 參數最多的是 24 個吧。
第二部分,引用 REGISTER 處理前四個參數。每次引用這四個參數的方式都是一樣:
REGISTER 參數,八位元的暫存器,十六位元的暫存器,三十二位元的暫存器,六十四位元的暫存器
REGISTER 巨集也是在 macros64.inc 裡面,但限於篇幅只列出部分內容,這部分內容在下面藍色框內。REGISTER 會檢查從 procedure_call 傳來的參數,也就是 anum,看看它的前幾個字元是否為⑴「ADDR」、⑵「"」、⑶「BYTE PTR」、⑷「WORD PTR」、⑸「DWORD PTR」、⑹「QWORD PTR」
REGISTER MACRO anum,breg,wreg,dreg,qreg ⁝ ssize SIZESTR <anum> ⁝ IF ssize GT 4 ;; handle ADDR notation lead SUBSTR <anum>,1,4 IFIDNI lead,<ADDR> wrd2 SUBSTR <anum>,6 lea qreg, wrd2 goto elbl ENDIF ENDIF IF ssize GT 1 ;; handle quoted text lead SUBSTR <anum>,1,1 IFIDNI lead,<"> mov qreg, reparg(anum) goto elbl ENDIF ENDIF ⁝ IF getattr(anum) EQ IMM ;; IMMEDIATE mov qreg, anum goto elbl ENDIF ⁝ ENDM
⑴:要測試前幾個字元是否為「ADDR」,那麼先檢查參數是否超過四 ( 因為 ADDR 有四個字元,其後必定還有其他字元,故一定超過四 )。如果超過,再檢查前四個字元是否為「ADDR」,如果是,那麼使 wrd2 為扣除「ADDR 」之後的字串,也就是 wrd2 為參數第六個字元開始到結尾所形成的字串 ( 因為第五個字元是空白 )。接著就是用 LEA 指令求出 wrd2 的位址,存於暫存器內。程式碼如右白色部分。
⑵:檢查參數是否為一字串,也就是以「"」起頭。跟上面步驟幾乎一樣,先檢查參數長度是否超過一,如果超過那麼要引用 reparg 巨集函式。程式碼如右紅色部分。
下面黃色部分的程式碼是 reparg 巨集函式。前面幾行是檢查參數的第一個字元是否為「"」,如果是的話表示參數為一字串,先在資料區段中建立此字串,其名稱為 nustr,然後在此 nustr 字串之後再設立一個 pnu 變數,「pnu DQ nustr」,事實上,pnu 變數的內容就是 nustr 之位址,然後將此位址當做回傳值返回。
reparg MACRO arg
LOCAL nustr,pnu
LOCAL quot
quot SUBSTR <arg>,1,1
IFIDN quot,<"> ;; if 1st char = "
.data
align 16
nustr db arg,0 ;; write arg to .DATA section
pnu dq nustr ;; get pointer to it
.code
EXITM <pnu> ;; return the pointer
ELSE
EXITM <arg> ;; else return arg unmodified
ENDIF
ENDM⑶∼⑹:與⑴、⑵的過程差不多,就不詳述。
⑺:檢查參數是否為常數 ( 在組合語言中常常把常數稱為立即值,immediate )。這必須要利用 OPATTR 運算子。但是 REGISTER 卻是引用 getattr 巨集函式,見上面藍色框藍色部分的程式碼。但如果真的去搜尋 getattr,會發現它只有一道指令「EXITM % opattr(arg)」,arg 為其參數。如果回傳值是 36 ( IMM 在 macros64.inc 有定義,其值為「36」),表示為常數,直接將此常數移入暫存器即可。
⑻∼⑼:與⑺的過程差不多,就不詳述。
大致瞭解巨集的運作之後,接下來就是實作了。利用 MASM64 SDK 所提供的包含檔,就能實現在 MASM 6.x 版的 invoke 高階語法,不必再費心去計算堆疊、呼叫方式等煩人的問題。在往後的幾章裡,都會採用這種方式撰寫 Win64 程式。
以 MASM64 SDK 的包含檔撰寫組合語言程式,算是非常容易的,只要在原始程式的第一行寫上「INCLUDE \masm32\include64\masm64rt.inc」,所有包含檔、匯入程式庫以及所有設定都自動完成。底下就是把第三章的 GREETING.ASM 以 MASM64 SDK 方式改寫:
1 2 3 4
5 6 7 8
9 10 11 12
13 14 15 16
17 18 19 20
21 22 23 24
25 26 27 28
29 30 31 32
33 34 35 36
37 38 39 40
41 42 43 44
45 46 47 48
49 50 |
INCLUDE \masm32\include64\masm64rt.inc
MAX_NAME EQU 4*2+2 ;中文姓名最多四個中文字,每個中文字佔兩個位元組,再加上0dH、0aH
;***************************************************************************************************
.CONST
sName DB "請輸入您的姓名(最多四個中文字):"
sHowAreYou DB ",您好嗎?"
;***************************************************************************************************
.DATA
hOutput DQ ? ;標準輸出裝置代碼
hInput DQ ? ;標準輸入裝置代碼
qWritten DQ ?
qRead DQ ?
sBuffer DB MAX_NAME+SIZEOF sHowAreYou DUP (0)
;***************************************************************************************************
.CODE
;---------------------------------------------------------------------------------------------------
main PROC
;獲得標準輸出/輸入裝置代碼,分別存入hOutput、hInput變數中
invoke GetStdHandle,STD_OUTPUT_HANDLE
cmp rax,INVALID_HANDLE_VALUE
je exit
mov hOutput,rax
invoke GetStdHandle,STD_INPUT_HANDLE
cmp rax,INVALID_HANDLE_VALUE
je exit
mov hInput,rax
;在標準輸出裝置上,印出sName字串,當做提示讓使用者明白該輸入什麼
invoke WriteConsole,hOutput,ADDR sName,SIZEOF sName,ADDR qWritten,0
;在標準輸入裝置上讀取字串。最多讀取 (MAX_NAME-2) 個位元組,實際讀取字串的位元組個數存於qRead變數中
invoke ReadConsole,hInput,ADDR sBuffer,MAX_NAME,ADDR qRead,0
;把sHowAreYou字串搬移到使用者輸入的姓名之後的位址
sub qRead,2 ;實際讀取字串的位元組個數,不包含0dH、0aH
mov rdi,OFFSET sBuffer
add rdi,qRead ;RDI=使用者輸入的姓名之後的位址
mov rcx,SIZEOF sHowAreYou
mov rsi,OFFSET sHowAreYou
mov r8,rcx
cld
rep movsb
add r8,qRead ;R8=sHowAreYou字串長度加上不包含0dH、0aH的姓名長度
invoke WriteConsole,hOutput,ADDR sBuffer,r8,ADDR qWritten,0
exit: invoke ExitProcess,0
main ENDP
;***************************************************************************************************
END |
把上面原始程式儲存成 GREETING2.ASM,以下面方式組譯及連結:
E:\HomePage\SOURCE\Win64>SET LINK=/SUBSYSTEM:CONSOLE /ENTRY:main [Enter] E:\HomePage\SOURCE\Win64>PATH E:\masm32\bin64;%path% [Enter] E:\HomePage\SOURCE\Win64>cd CONSOLE [Enter] E:\HomePage\SOURCE\Win64\CONSOLE>ml64 greeting2.asm [Enter] Microsoft (R) Macro Assembler (x64) Version 14.25.28614.0 Copyright (C) Microsoft Corporation. All rights reserved. Assembling: greeting2.asm Microsoft (R) Incremental Linker Version 14.25.28614.0 Copyright (C) Microsoft Corporation. All rights reserved. /SUBSYSTEM:CONSOLE /ENTRY:main /OUT:greeting2.exe greeting2.obj E:\HomePage\SOURCE\Win64\CONSOLE>greeting2 [Enter] 請輸入您的姓名(最多四個中文字):小木偶 [Enter] 小木偶,您好嗎? E:\HomePage\SOURCE\Win64\CONSOLE>
底下說明在 MASM64 SDK 中,先進所打造的 invoke 巨集之用法。先來看看它的語法:
invoke 副程式名或 Windows API 名稱,參數列表
參數列表中的參數個數並不固定,依據副程式或 Windows API 的需要,參數之間以「,」分隔。參數列表之中的參數,可分為幾類:①常數(或立即值)、②變數(包含全域變數跟區域變數)、③暫存器、④常數或變數的位址、⑤字串。前三類都可以直接寫在參數列表之中。第④類必須在代表位址的常數或變數名稱前加上「ADDR」;第⑤類是字串,必須以一對「"」將字串括住。例如底下的例子(greeting2.asm 第 29 行):
invoke WriteConsole,hOutput,ADDR sName,SIZEOF sName,ADDR qWritten,0
第一個參數,hOutput 是變數,直接寫在參數列表中;第二個參數是字串常數,sName,的位址,前面加「ADDR」;第三個參數是 sName 的長度,先用「SIZEOF」求出來,然後可視為常數,因此寫成「SIZEOF sName」;接下來的參數是變數位址,故要加上「ADDR」;最後一個參數是常數,直接寫上即可。
副程式與巨集都可以讓原始程式變得精簡,看起來更為清楚。但是它們之間還是有些不同,這裡列出下面幾點不同:
上面的幾個項目中,可能有些難以描述,也不容易體會。但沒關係,隨著經驗增加,會慢慢瞭解。下面幾章的程式範例,都會以ML64.EXE 搭配 MASM64 SDK 包含檔,來撰寫 Win64 程式。
有時候一個變數需要有兩個名稱,或是只需要指定某個位址時,可以用「LABEL」假指令。LABEL 的語法是:
符號名 LABEL 資料類型
LABEL 會把符號名指定為後面的資料類型,但是卻不分配記憶體空間。上面的資料類型可以是 BYTE、WORD、DWORD、QWORD 等 MASM 已定義的資料類型。例如底下的例子:
.DATA
x LABEL DWORD
y QWORD 1111222233334444h
⁝
mov eax,x
mov rcx,y
x、y 這兩個變數的位址都相同,但是 x 的長度是雙字組,y 是四字組。因此上述程式執行後,x 為 33334444H,y 為 1111222233334444H。
在 REPEAT/ENDM 假指令的例子中,原本的程式碼是:
letter ="a"
counter =26
alpha LABEL BYTE
REPEAT counter
DB letter
letter =letter+1
ENDM
組譯後,產生的程式碼是:
alpha LABEL BYTE
DB "abcdefghijklmnopqrstuvwxyz"
雖然在 DB 假指令之前,沒有寫出字串的名稱,但是上一行的「alpha LABEL BYTE」宣告了 alpha 變數的位址就是與 DB 定義的字串位址相同。因此在往後的原始程式中,提到 alpha,其實就是這個字串。